
{kind=link}
On this article, you’ll learn the way a transformer converts enter tokens into context-aware representations and, finally, next-token chances.
Matters we are going to cowl embrace:
- How tokenization, embeddings, and positional info put together inputs
- What multi-headed consideration and feed-forward networks contribute inside every layer
- How the ultimate projection and softmax produce next-token chances
Let’s get our journey underway.
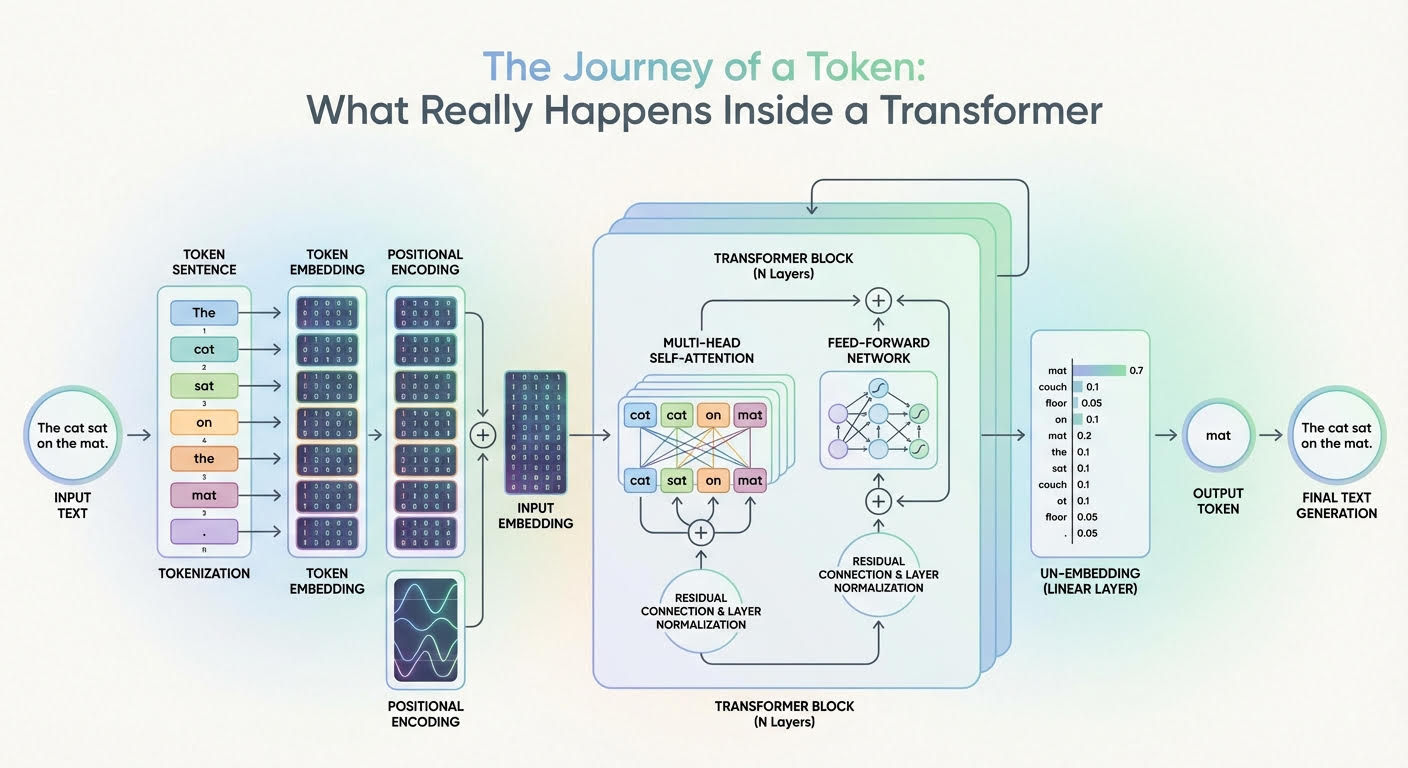
The Journey of a Token: What Actually Occurs Inside a Transformer (click on to enlarge)
Picture by Editor
The Journey Begins
Giant language fashions (LLMs) are based mostly on the transformer structure, a posh deep neural community whose enter is a sequence of token embeddings. After a deep course of — that appears like a parade of quite a few stacked consideration and feed-forward transformations — it outputs a chance distribution that signifies which token needs to be generated subsequent as a part of the mannequin’s response. However how can this journey from inputs to outputs be defined for a single token within the enter sequence?
On this article, you’ll study what occurs inside a transformer mannequin — the structure behind LLMs — on the token degree. In different phrases, we are going to see how enter tokens or elements of an enter textual content sequence flip into generated textual content outputs, and the rationale behind the adjustments and transformations that happen contained in the transformer.
The outline of this journey by a transformer mannequin can be guided by the above diagram that reveals a generic transformer structure and the way info flows and evolves by it.
Coming into the Transformer: From Uncooked Enter Textual content to Enter Embedding
Earlier than getting into the depths of the transformer mannequin, a number of transformations already occur to the textual content enter, primarily so it’s represented in a kind that’s absolutely comprehensible by the interior layers of the transformer.
Tokenization
The tokenizer is an algorithmic part sometimes working in symbiosis with the LLM’s transformer mannequin. It takes the uncooked textual content sequence, e.g. the consumer immediate, and splits it into discrete tokens (typically subword models or bytes, generally complete phrases), with every token within the supply language being mapped to an identifier i.
Token Embeddings
There’s a discovered embedding desk E with form |V| × d (vocabulary measurement by embedding dimension). Trying up the identifiers for a sequence of size n yields an embedding matrix X with form n × d. That’s, every token identifier is mapped to a d-dimensional embedding vector that varieties one row of X. Two embedding vectors can be related to one another if they’re related to tokens which have related meanings, e.g. king and emperor, or vice versa. Importantly, at this stage, every token embedding carries semantic and lexical info for that single token, with out incorporating details about the remainder of the sequence (a minimum of not but).
Positional Encoding
Earlier than absolutely getting into the core elements of the transformer, it’s essential to inject inside every token embedding vector — i.e. inside every row of the embedding matrix X — details about the place of that token within the sequence. That is additionally known as injecting positional info, and it’s sometimes finished with trigonometric capabilities like sine and cosine, though there are strategies based mostly on discovered positional embeddings as properly. A virtually-residual part is summed to the earlier embedding vector e_t related to a token, as follows:
[
x_t^{(0)} = e_t + p_{text{pos}}(t)
]
with p_pos(t) sometimes being a trigonometric-based perform of the token place t within the sequence. Because of this, an embedding vector that previously encoded “what a token is” solely now encodes “what the token is and the place within the sequence it sits”. That is equal to the “enter embedding” block within the above diagram.
Now, time to enter the depths of the transformer and see what occurs inside!
Deep Contained in the Transformer: From Enter Embedding to Output Possibilities
Let’s clarify what occurs to every “enriched” single-token embedding vector because it goes by one transformer layer, after which zoom out to explain what occurs throughout your entire stack of layers.
The method
[
h_t^{(0)} = x_t^{(0)}
]
is used to indicate a token’s illustration at layer 0 (the primary layer), whereas extra generically we are going to use ht(l) to indicate the token’s embedding illustration at layer l.
Multi-headed Consideration
The primary main part inside every replicated layer of the transformer is the multi-headed consideration. That is arguably probably the most influential part in your entire structure in the case of figuring out and incorporating into every token’s illustration loads of significant details about its function in your entire sequence and its relationships with different tokens within the textual content, be it syntactic, semantic, or every other type of linguistic relationship. A number of heads on this so-called consideration mechanism are every specialised in capturing totally different linguistic features and patterns within the token and your entire sequence it belongs to concurrently.
The results of having a token illustration ht(l) (with positional info injected a priori, don’t overlook!) touring by this multi-headed consideration inside a layer is a context-enriched or context-aware token illustration. By utilizing residual connections and layer normalizations throughout the transformer layer, newly generated vectors develop into stabilized blends of their very own earlier representations and the multi-headed consideration output. This helps enhance coherence all through your entire course of, which is utilized repeatedly throughout layers.
Feed-forward Neural Community
Subsequent comes one thing comparatively much less advanced: a number of feed-forward neural community (FFN) layers. As an illustration, these could be per-token multilayer perceptrons (MLPs) whose objective is to additional rework and refine the token options which can be regularly being discovered.
The primary distinction between the eye stage and this one is that spotlight mixes and incorporates, in every token illustration, contextual info from throughout all tokens, however the FFN step is utilized independently on every token, refining the contextual patterns already built-in to yield helpful “information” from them. These layers are additionally supplemented with residual connections and layer normalizations, and because of this course of, we have now on the finish of a transformer layer an up to date illustration ht(l+1) that may develop into the enter to the subsequent transformer layer, thereby getting into one other multi-headed consideration block.
The entire course of is repeated as many instances because the variety of stacked layers outlined in our structure, thus progressively enriching the token embedding with increasingly higher-level, summary, and long-range linguistic info behind these seemingly indecipherable numbers.
Closing Vacation spot
So, what occurs on the very finish? On the high of the stack, after going by the final replicated transformer layer, we receive a closing token illustration ht*(L) (the place t* denotes the present prediction place) that’s projected by a linear output layer adopted by a softmax.
The linear layer produces unnormalized scores known as logits, and the softmax converts these logits into next-token chances.
Logits computation:
[
text{logits}_j = W_{text{vocab}, j} cdot h_{t^*}^{(L)} + b_j
]
Making use of softmax to calculate normalized chances:
[
text{softmax}(text{logits})_j = frac{exp(text{logits}_j)}{sum_{k} exp(text{logits}_k)}
]
Utilizing softmax outputs as next-token chances:
[
P(text{token} = j) = text{softmax}(text{logits})_j
]
These chances are calculated for all potential tokens within the vocabulary. The subsequent token to be generated by the LLM is then chosen — typically the one with the very best chance, although sampling-based decoding methods are additionally frequent.
Journey’s Finish
This text took a journey, with a delicate degree of technical element, by the transformer structure to supply a basic understanding of what occurs to the textual content that’s supplied to an LLM — probably the most outstanding mannequin based mostly on a transformer structure — and the way this textual content is processed and remodeled contained in the mannequin on the token degree to lastly flip right into a mannequin’s output: the subsequent phrase to generate.
We hope you’ve gotten loved our travels collectively, and we sit up for the chance to embark upon one other within the close to future.