
{kind=link}
On this article, you’ll study 5 sensible immediate compression strategies that cut back tokens and pace up giant language mannequin (LLM) technology with out sacrificing process high quality.
Matters we are going to cowl embrace:
- What semantic summarization is and when to make use of it
- How structured prompting, relevance filtering, and instruction referencing reduce token counts
- The place template abstraction matches and methods to apply it persistently
Let’s discover these strategies.
Immediate Compression for LLM Technology Optimization and Value Discount
Picture by Editor
Introduction
Giant language fashions (LLMs) are primarily educated to generate textual content responses to consumer queries or prompts, with advanced reasoning below the hood that not solely includes language technology by predicting every subsequent token within the output sequence, but additionally entails a deep understanding of the linguistic patterns surrounding the consumer enter textual content.
Immediate compression strategies are a analysis subject that has these days gained consideration throughout the LLM panorama, because of the have to alleviate gradual, time-consuming inference brought on by bigger consumer prompts and context home windows. These strategies are designed to assist lower token utilization, speed up token technology, and cut back total computation prices whereas protecting the standard of the duty consequence as a lot as attainable.
This text presents and describes 5 generally used immediate compression strategies to hurry up LLM technology in difficult eventualities.
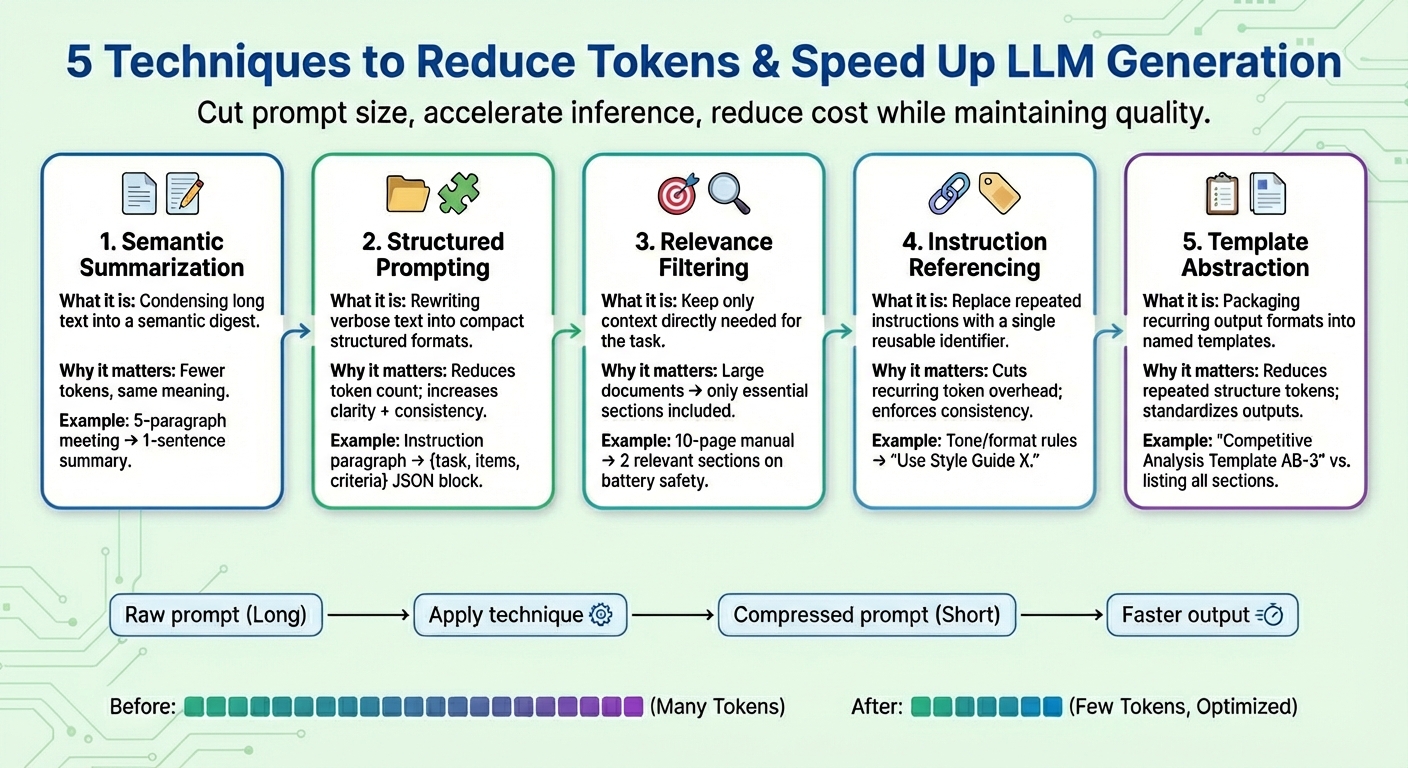
1. Semantic Summarization
Semantic summarization is a way that condenses lengthy or repetitive content material right into a extra succinct model whereas retaining its important semantics. Reasonably than feeding your complete dialog or textual content paperwork to the mannequin iteratively, a digest containing solely the necessities is handed. The end result: the variety of enter tokens the mannequin has to “learn” turns into decrease, thereby accelerating the next-token technology course of and lowering price with out dropping key data.
Suppose an extended immediate context consisting of assembly minutes, like “In yesterday’s assembly, Iván reviewed the quarterly numbers…”, summing as much as 5 paragraphs. After semantic summarization, the shortened context could appear to be “Abstract: Iván reviewed quarterly numbers, highlighted a gross sales dip in This fall, and proposed cost-saving measures.”
2. Structured (JSON) Prompting
This method focuses on expressing lengthy, easily flowing items of textual content data in compact, semi-structured codecs like JSON (i.e., key–worth pairs) or an inventory of bullet factors. The goal codecs used for structured prompting sometimes entail a discount within the variety of tokens. This helps the mannequin interpret consumer directions extra reliably and, consequently, enhances mannequin consistency and reduces ambiguity whereas additionally lowering prompts alongside the way in which.
Structured prompting algorithms could rework uncooked prompts with directions like Please present an in depth comparability between Product X and Product Y, specializing in worth, product options, and buyer scores right into a structured kind like: {process: “evaluate”, gadgets: [“Product X”, “Product Y”], standards: [“price”, “features”, “ratings”]}
3. Relevance Filtering
Relevance filtering applies the precept of “specializing in what actually issues”: it measures relevance in components of the textual content and incorporates within the remaining immediate solely the items of context which might be actually related for the duty at hand. Reasonably than dumping whole items of data like paperwork which might be a part of the context, solely small subsets of the knowledge which might be most associated to the goal request are stored. That is one other strategy to drastically cut back immediate dimension and assist the mannequin behave higher by way of focus and boosted prediction accuracy (bear in mind, LLM token technology is, in essence, a next-word prediction process repeated many instances).
Take, for instance, a complete 10-page product guide for a cellphone being added as an attachment (immediate context). After making use of relevance filtering, solely a few brief related sections about “battery life” and “charging course of” are retained as a result of the consumer was prompted about security implications when charging the system.
4. Instruction Referencing
Many prompts repeat the identical sorts of instructions time and again, e.g., “undertake this tone,” “reply on this format,” or “use concise sentences,” to call just a few. Instruction referencing creates a reference for every widespread instruction (consisting of a set of tokens), registers each solely as soon as, and reuses it as a single token identifier. Every time future prompts point out a registered “widespread request,” that identifier is used. In addition to shortening prompts, this technique additionally helps preserve constant process conduct over time.
A mixed set of directions like “Write in a pleasant tone. Keep away from jargon. Maintain sentences succinct. Present examples.” could possibly be simplified as “Use Type Information X.” after which be reused when the equal directions are specified once more.
5. Template Abstraction
Some patterns or directions usually seem throughout prompts — as an example, report buildings, analysis codecs, or step-by-step procedures. Template abstraction applies an identical precept to instruction referencing, however it focuses on what form and format the generated outputs ought to have, encapsulating these widespread patterns below a template identify. Then template referencing is used, and the LLM does the job of filling the remainder of the knowledge. Not solely does this contribute to protecting prompts clearer, it additionally dramatically reduces the presence of repeated tokens.
After template abstraction, a immediate could also be changed into one thing like “Produce a Aggressive Evaluation utilizing Template AB-3.” the place AB-3 is an inventory of requested content material sections for the evaluation, each being clearly outlined. One thing like:
Produce a aggressive evaluation with 4 sections:
- Market Overview (2–3 paragraphs summarizing trade tendencies)
- Competitor Breakdown (desk evaluating no less than 5 rivals)
- Strengths and Weaknesses (bullet factors)
- Strategic Suggestions (3 actionable steps).
Wrapping Up
This text presents and describes 5 generally used methods to hurry up LLM technology in difficult eventualities by compressing consumer prompts, usually specializing in the context a part of it, which is most of the time the foundation reason behind “overloaded prompts” inflicting LLMs to decelerate.